长文本推理的隐忧:KVCache压缩算法是否正陷入“平均值陷阱”?
在大模型长上下文推理不断演进的当下,KVCache压缩技术几乎成为了提升算力效率的“救命稻草”。然而,当我们沉浸在各种压缩算法刷榜的喜悦中时,是否真正审视过这些技术底层的脆弱性?中科大研究团队在ICLR2026发表的DefensiveKV研究,犹如一盆冷水,浇醒了沉迷于“平均指标”的开发者群体。他们通过严谨的实验揭示了一个令人不安的事实:当前主流的压缩方法,其底层假设可能从一开始就是错误的。
稳定性假设的幻觉
长期以来,学术界与工业界在优化KVCache时,普遍遵循着一个看似金科玉律的逻辑:历史窗口内的平均重要性,足以代表token的价值。基于此,大部分算法通过观测一段历史,淘汰那些“平均重要性低”的cache。然而,这种逻辑预设了一个前提——重要性是随时间稳定的。DefensiveKV团队通过数据可视化清晰地指出,这种假设在真实长文本任务中频繁崩溃。在某些关键时间窗口,被判定为“重要”的cache甚至无法达到整体重要性的半数,这种“稳定性崩溃”在单次回复中竟然高达65次。这不禁让人反思,我们所追求的性能提升,是否仅仅是基于统计学上的“幸存者偏差”?
从盲目优化到风险控制的思维转向
这种现象与金融投资中的教训如出一辙:只关注平均收益,却无视极端风险,最终往往会导致系统性溃败。当算法在平稳期表现尚可,却在关键时刻掉链子时,其工程落地价值便大打折扣。DefensiveKV团队提出的“防御性聚合”策略,实际上是一次认知上的拨乱反正。他们摒弃了对平均值的盲目崇拜,转而拥抱最坏风险控制思维。这种转变的核心在于,不再试图通过预测未来去筛选token,而是通过最大化风险覆盖,确保那些可能在未来发挥关键作用的信息不会被轻易丢弃。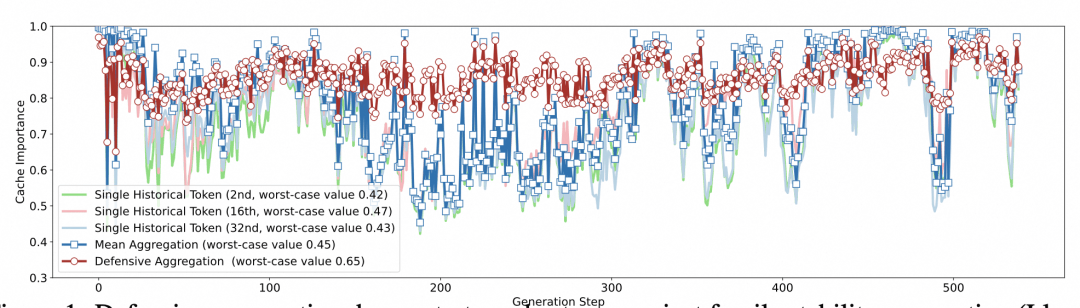
极简代码背后的算法哲学
最令业界称道的是,实现这一防御性逻辑并不需要复杂的架构重构,仅仅两行代码的改动便能产生质变。其一,最坏风险估计,通过“取最大”的方式,将历史中的高光时刻视为未来风险的预警,这是一种典型的“宁可错留,不可错删”的工程智慧。其二,自适应先验风险修正,借鉴贝叶斯平滑思想,为观测不足的token提供了保底机制。这种设计不仅计算复杂度极低,更在实际测试中展现出了惊人的鲁棒性,将最坏情况下的保留重要性分数从0.45提升至0.65,这种提升在追求极致性能的AI领域显得尤为珍贵。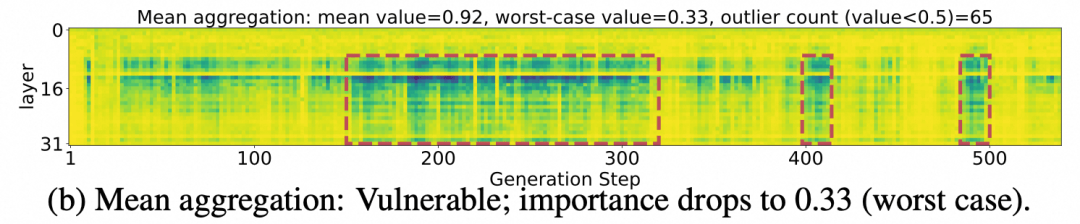
关于算法鲁棒性的深度拷问
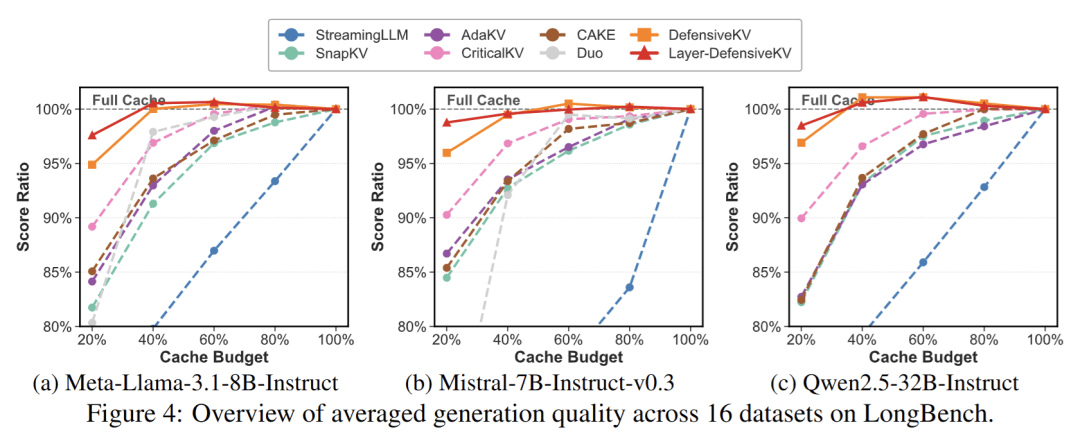
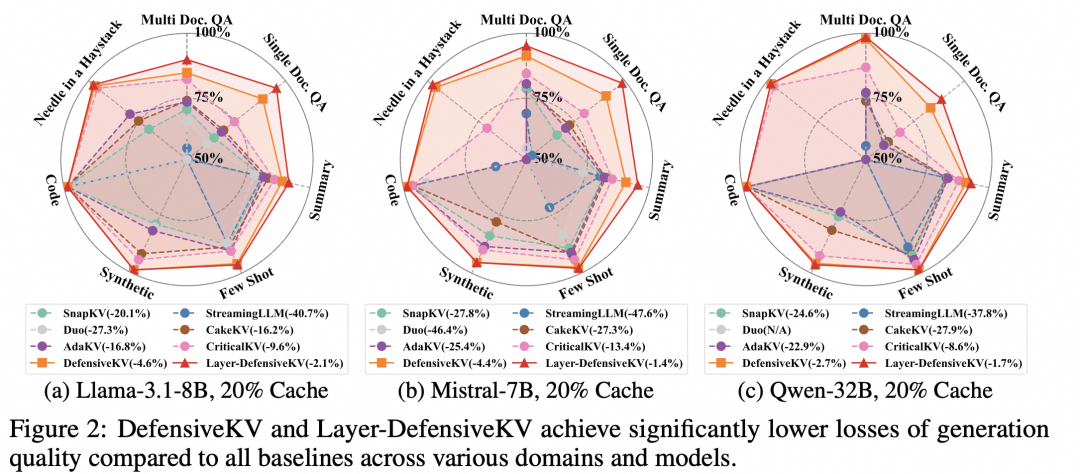
我们是否在过度追求压缩率的道路上,牺牲了模型的稳定性?DefensiveKV的出现,不仅刷新了Llama-3.1-8B等模型的性能边界,更重要的是它向业界抛出了一个深刻的问题:在算法迭代中,我们应该优先优化什么?是那个好看的平均值指标,还是那个决定模型在极端复杂任务中表现的鲁棒性?通过对CriticalKV等基线的改进,团队证明了防御性策略具有普适的叠加效应。这种正交化的设计,意味着未来所有的压缩算法,都可以在保留原有逻辑的基础上,通过引入防御性聚合来增强自身能力。对于开发者而言,这不仅仅是一个工具的更新,更是一次关于AI工程落地思维的深刻洗礼。
技术演进的必然趋势
重塑评估体系的必要性
当前的基准测试往往掩盖了算法的真实脆弱性,许多声称“无损”的方案在严苛环境下即刻原形毕露。这一发现迫使我们必须重新评估现有的性能评价指标。我们不能仅满足于平均水平的提升,更应关注算法在最坏情况下的保底能力。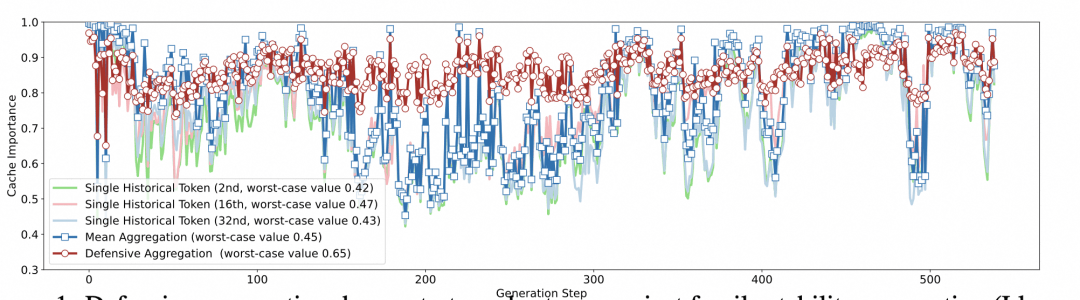
防御性思维的泛化应用
这种“防御性聚合”的思路不仅局限于KVCache压缩,未来在模型量化、剪枝等领域,或许同样可以引入类似的风险控制机制。与其在复杂性上做文章,不如在工程鲁棒性上深耕,这才是通往高效、稳定长文本推理的必由之路。